코딩/JSP
#1 JSP- jsoup 크롤링
NTART
2020. 7. 29. 07:38
파이썬에 BeautifulSoup이 있다면 자바에는 jsoup 웹 크롤러가 있다.
1. 세팅

https://jsoup.org/download 에서 라이브러리를 다운받아
lib 폴더안에 넣어줘야 한다.
<%@ page import="org.jsoup.Jsoup" %>
<%@ page import="org.jsoup.nodes.Document" %>
<%@ page import="org.jsoup.nodes.Element" %>
<%@ page import="org.jsoup.select.Elements" %>그리고 위 네 문장을 import 해주면 jsp에서 jsoup 사용이 가능해진다.
2. 페이지 탐색

네이버에서 정보처리기사를 검색하면 일정표가 나온다. 이 부분을 크롤링해 볼 것이다.

하위로 까내려가 보면, 해당 class 부분을 찾을 수 있다.

파싱할 내용들은 예상대로 td 속성 안에 들어있는 것을 확인할 수 있다.
그리고 파싱할 필요가 없어보이는 알림 부분(네이버 알림 기능)의 class도 확인하였다.
3. 코드 작성
<%
Document doc = Jsoup.connect("https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EC%A0%95%EB%B3%B4%EC%B2%98%EB%A6%AC%EA%B8%B0%EC%82%AC").get();
// 파싱할 사이트를 적어, 모든 태그를 가져온다.
Elements posts = doc.body().getElementsByClass("sc cs_language_test _sc_language_test");
// sc cs_language_test _sc_language_test속성의 모든 태그를 가져온다.
int i=0;
for(Element e : posts.select("td:not(.align_center)")){
//td 속성 요소값들을 반복해서 출력(td속성 갯수만큼), :not을 통해 align_center class의 td 요소는 제외 (알림 부분)
out.println(e.text());
out.println("|"); //복잡해져 구분을 위함
i++;
if(i==2){
out.println("<br>"); //마찬가지로 문자열을 다듬어주었다.
i=0;
}
}
%>cf) class는 . id는 #

웹페이지에 크롤링된 값들이 출력되는 모습을 볼 수 있다.
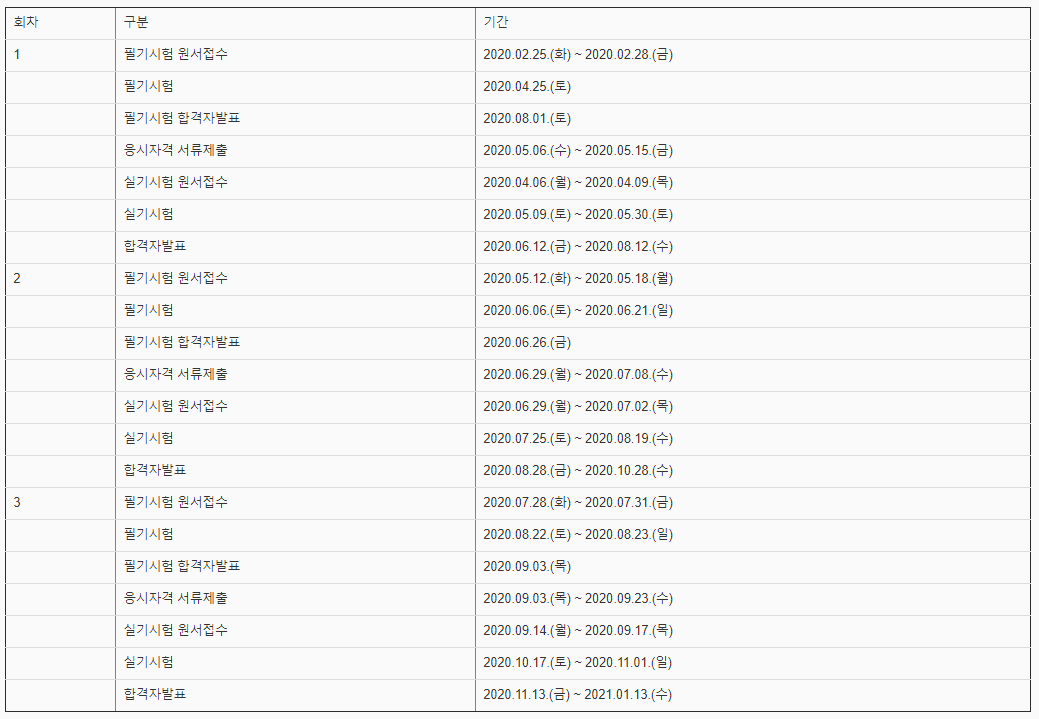
테이블을 만들어 크롤링한 값들을 쏙쏙 넣게끔 정리하였다.